
Scrapping movie data from static web
Every data science journey starts by aggregating the data of interest. In the industry sector, those are often coming directly from sensors, user surveys, software or application used by your customers. Nonetheless, the information publicly available on the web still remain an important source of additional information like news, weather or even geographical addresses. Today, we will focus on movie data...
In this post, I will present some techniques to scrap static web pages in python 3. In this context, static mean pages for which the information is not dynamically generated by the web browser (using i.e. javascript functions) but are instead generated on the server-side and don't require your browser to dynamically generate information. Dynamic website scrapping will be addressed in a different post.
For this showcase, we will scrap a well-known french website of movie reviews. For all accessible movies, we will collect the movie director, the main actors, the movie title, and synopsis and some additional information like the release date, the duration of the movie, the type of movie (drama, comedy...). In addition, we will also collect user reviews (score and critics) for each movie. The name of the movie review website that is used is not mentioned on purpose in order to avoid massive load on their servers. Nevertheless, the techniques described here can be used on your favorite website.
In python 3, the easiest way to access the content of a web page is via the urllib.request package. See bellow a typical example to scrap the google page. Note that we provide the "User-Agent" Http header in the Request constructor because many websites only allow access to their content to well-known web browser ( Google Chrome in this case).
from urllib.request import urlopen, Request
url = "http://www.google.com"
try:
req = urllib.request.Request(url, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)'})
pageHtml = urllib.request.urlopen(req, timeout=5)
print(pageHtml.read()) #print the text of the page
pageHtml.close()
except Exception as e:
#handle for timeout, wrong URL, wrong permission, etc.
print("Exception with url " + str(url)+" at line " + str(sys.exc_info()[-1].tb_lineno) + "\n" +str(e))
If you try to run the above code, you will see that what we receive is nothing but the Html code of the google page. That's all we need as the information we are looking for is hidden somewhere inside there. Many packages are available in python to help us navigate within the Html code and help us to collect the information we need. The most convenient (and famous) to use is BeautifulSoup. We can build a BeautifulSoup object from our web page using the following code:
from bs4 import BeautifulSoup
page = BeautifulSoup( pageHtml , "lxml")
print(page.body.get_text(" ", strip=True)) #print all the text found on the webpage
What is particularly interesting with BeautifulSoup is that we can easily search for all Html object on the page with a given class name. In modern web design, class name is very often used to categorize the different object displayed on a page. In the case that interest us, movie review website are often constructed as a table of movie where each row contains the information we are interested in. If we continue with the google example, we can easily retrieve the search text entry by inspecting the web page in a web browser (I used chrome). This is made easy by right clicking on the element for which we can to retrieve the class name and selecting "inspect" in the contextual menu. The code of the element is highlighted on the right inspection tab. The class name is generally one of the first entry of the block.
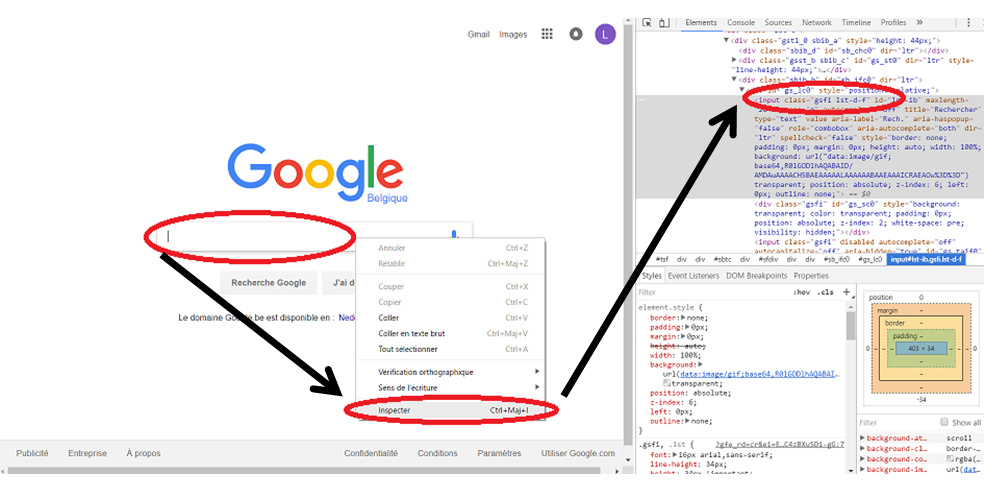 Retrieving the class name of an object on a page is very simple thanks to the "inspect" option of modern web browsers.[/caption]
Retrieving the class name of an object on a page is very simple thanks to the "inspect" option of modern web browsers.[/caption]
We can then access this element from our code by searching for all elements which have a class name "gsfi" using BeautifulSoup find_all method. It returns a list of found object.
searchEntries = page.body.find_all(class_="gsfi", recursive=True)
if(len(searchEntries)==0): print("Object was not found on page")
On more complex web page (i.e. movie review sites) we can then loop on all the object found in order to extract the information we are looking for using the get_text method.
for entry in searchEntries:
print("Found an entry with text" + entry.get_text(" ", strip=True))
We now have all the ingredients to scrap any type of static web page. So it's probably a good time to remind that they are some good practice to follow when we scrap a website. Many information and details are available on scraphero, but for me, the more important advices are:
- Don't go too fast: If you try to load too many pages at the same time, you have good chances to saturate the server and to be banned forever from the website.
- Follow the rules provided by the robot.txt file of the website. This file indicates what is allowed in terms of scrapping on their website.
We can now proceed and collect our movie data...
As explained earlier, I am not going to give specific code in order to preserve the movie website server. However, I can show some of the information collected and some of the fun we can have with them. Bellows are three example of extracted movies out of the 70000 movies (~1GB of data) I collected.
Elysium: Synopsis: En 2154, il existe deux catégories de personnes : ceux très riches, qui vivent sur la parfaite station spatiale crée par les hommes appelée Elysium, et les autres, ceux qui vivent sur la Terre devenue surpeuplée et ruinée. Director: Neill Blomkamp Actors: Matt Damon , Jodie Foster , Sharlto Copley Extra data: 14 août 2013 / 1h 50min / Science fiction , Action , Thriller
Le Père Noël est une ordure: Synopsis: La permanence téléphonique parisienne SOS détresse-amitié est perturbée le soir de Noël par l'arrivée de personnages marginaux farfelus qui provoquent des catastrophes en chaîne. Director: Jean-Marie Poiré Actors: Anémone , Josiane Balasko , Marie-Anne Chazel Extra data: 25 août 1982 / 1h 23min / Comédie
Expendables 3: Synopsis: Barney, Christmas et le reste de l’équipe affrontent Conrad Stonebanks, qui fut autrefois le fondateur des Expendables avec Barney. Stonebanks devint par la suite un redoutable trafiquant d’armes, que Barney fut obligé d’abattre… Du moins, c’est ce qu’il croyait. Director: Patrick Hughes (II) Actors: Sylvester Stallone , Jason Statham , Arnold Schwarzenegger Extra data: 20 août 2014 / 2h 07min / Action
As you can see the movie details are quite complete. I have not listed there the user reviews associated with these movies are they are many reviews for each move and that those are often very lengthy. Nonetheless, we have the data and can use them if needed.
We can now perform some analysis on these data in order to find insights,
Who are the directors who have made more movie?
- John Ford : 84 movies
- Raoul Ruiz : 66 movies
- Kenji Mizoguchi : 63 movies
- Henry Hathaway : 57 movies
- Jesús Franco : 56 movies
- Julien Duvivier : 54 movies
- Claude Chabrol : 53 movies
- Jean-Pierre Mocky : 52 movies
- Seijun Suzuki : 52 movies
- Raoul Walsh : 51 movies
Who are the actors who have played in more movie ?
- Gérard Depardieu : 116 movies
- Michel Piccoli : 107 movies
- Catherine Deneuve : 102 movies
- Robert De Niro : 90 movies
- Bernard Blier : 89 movies
- Jean Gabin : 88 movies
- Michel Serrault : 86 movies
- Fernandel : 84 movies
- Jean-Louis Trintignant : 83 movies
- Jeanne Moreau : 82 movies
Of course, we can see that french actors and directors appear in this top 10. This might be a bias induced by the "french" origin of the movie review site that we have scrapped. There is also a "temporal" bias as we considered all movies without time window. Making similar top 10 considering only movies produced in the last decade would lead to very different results.
What are all the movies where Tom Hanks played ? (in random order)
- The Circle (de James Ponsoldt)
- Les Monstres du labyrinthe (de Steven Hilliard Stern)
- Extrêmement fort et incroyablement près (de Stephen Daldry)
- Mister Showman (de Sean McGinly)
- Greyhound (de Aaron Schneider)
- Dans l'ombre de Mary - La promesse de Walt Disney (de John Lee Hancock)
- Il n'est jamais trop tard (de Tom Hanks)
- Turner & Hooch (de Roger Spottiswoode)
- Les Sentiers de la perdition (de Sam Mendes)
- Le Palace en folie (de Neal Israel)
- Misery Loves Comedy (de Kevin Pollak)
- Nuits blanches à Seattle (de Nora Ephron)
- Vous avez un message (de Nora Ephron)
- Capitaine Phillips (de Paul Greengrass)
- Every time we say goodbye (de Moshe Mizrahi)
- Les Banlieusards (de Joe Dante)
- Philadelphia (de Jonathan Demme)
- Toujours prêts (de Nicholas Meyer)
- Cloud Atlas (de Lilly Wachowski)
- La Guerre (de Lynn Novick)
- Sully (de Clint Eastwood)
- Joe contre le volcan (de John Patrick Shanley)
- Une Équipe hors du commun (de Penny Marshall)
- Big (de Penny Marshall)
- La Guerre selon Charlie Wilson (de Mike Nichols)
- Le Mot de la fin (de David Seltzer)
- Rien en commun (de Garry Marshall)
- And the Oscar goes to (de Jeffrey Friedman)
- Splash (de Ron Howard)
- Inferno (de Ron Howard)
- Anges et démons (de Ron Howard)
- Da Vinci Code (de Ron Howard)
- Apollo 13 (de Ron Howard)
- Dragnet (de Tom Mankiewicz)
- Le Bûcher des vanités (de Brian De Palma)
- Ithaca (de Meg Ryan)
- Il faut sauver le soldat Ryan (de Steven Spielberg)
- Arrête-moi si tu peux (de Steven Spielberg)
- Le Pont des Espions (de Steven Spielberg)
- Le Terminal (de Steven Spielberg)
- L'Homme à la chaussure rouge (de Stan Dragoti)
- Le Pôle Express (de Robert Zemeckis)
- Seul au monde (de Robert Zemeckis)
- Forrest Gump (de Robert Zemeckis)
- La Ligne verte (de Frank Darabont)
- A Hologram for the King (de Tom Tykwer)
- Une Baraque à tout casser (de Richard Benjamin)
- Ladykillers (de Ethan Coen)
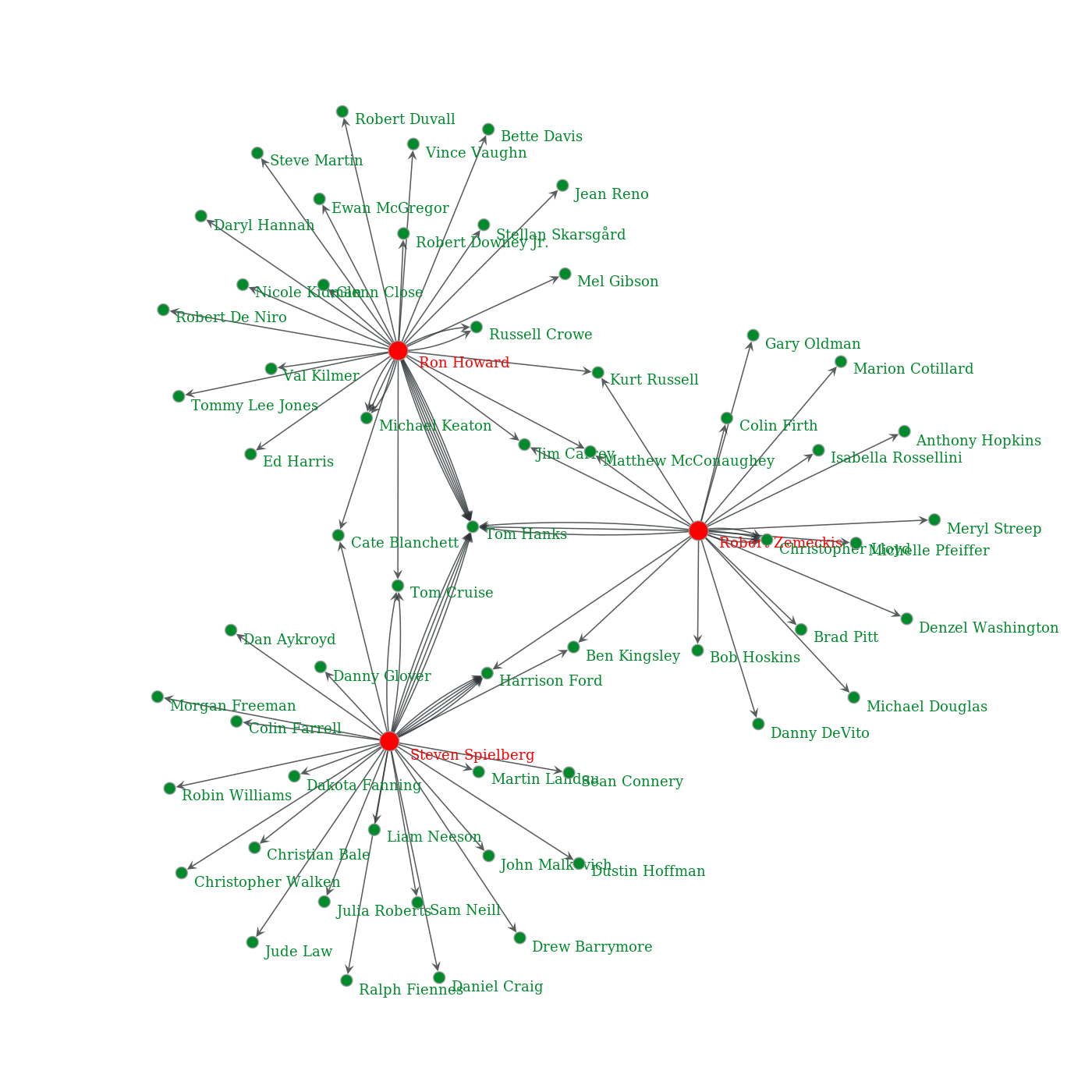
Who are the favorite actors of Steven Spielberg, Ron Howard and Robert Zemeckis ? and how many films do they have in common?
The figure bellow shows a graph network of the actor shared between these three directors. For clarity of the figures, only the actors that are in the top 500 actors are shown. Green dots symbolizes actors, red dots symbolizes directors and each line correspond to a movie which connects a director and an actor. When more than one line connects a director to an actor, it means that there are several movies connecting them.
Have you already faced similar type of issues ?
Feel free to contact us, we'd love talking to you…Don't forget to like and share if you found this helpful!