
Sentiment Analysis of French texts using deep learning techniques
In this blog, we will see how deep learning techniques (Recurrent Neural Network, RNN and/or Convolutional Neural Network, CNN) can be used to determine the sentiment polarity of a written text. This is call "sentiment analysis" and it's very useful to enhanced the communication with your customers. Such algorithms are typically used to analyze emails, website or even Facebook posts where your customers may talk about your products. Thanks to this, you can prioritize your answers and react faster to the unsatisfied customers...The web is full of blogs explaining how to perform polarity analysis on English texts. Unfortunately, most of these tutorials are not very useful to analyze text in other languages or contexts. These blogs either relies on:
- Classical Natural Language Processing (NLP) libraries trained by others for the sentiment analysis, like NLTK, Polyglot or the Standard NLP. And those are often limited to a specific list of languages and/or quickly become inefficient for specific (i.e. business) text context.
- Deep learning techniques using always the same IMDB dataset of movie reviews in English. Actually, this dataset can not even be used for commercial application (see the license on the IMDB website) and it can therefore not be used for business purposes. Moreover, depending on the type of text you are planning to analyze, it's certainly better to take a dataset which is closer to your business context. For instance, a movie reviews dataset won't be ideal if you own a restaurant/hotel and you'd like to know if your customers are satisfied by your services.
For these reasons, I decided to show how easy we can train a deep neural network to learn the sentiment behind a text in French. The technical aspects of this document are inspired by this excellent blog. Like there, I am using Keras with a Tensorflow backend. The main difference is coming from the training dataset used: they used the usual IMDB dataset, while I use a French dataset of movie reviews that I mined myself (see this previous blog post). The idea is to train our model to "read" a (movie review) text and predict what is the mark that is associated with this text (score of the movie). If we have enough pairs of review text - score to train the deep neural network, the algorithm will be capable of understanding which sequence of words have a positive meaning and which ones have a negative meaning. As there is no need to know the vocabulary and/or grammatical rules of the language in this learning process, it can be used for any language in the condition to have a large enough dataset to train the model.
Before feeding the neural network, we need to perform the traditional NLP pre-processing of the text (I don't enter into the details as this is very classical approach and it's already well documented on every single NLP blog):
- Texts are chunked in words based on white space, punctuation, etc. This is done using a Treebank tokenizer of the NLTK library (nltk.tokenize.word_tokenize).
- Characters are turned to lowercase, as I don't want the algorithm to identify the word polarity based on its capitalization. (Although it could help sometimes).
- A dictionary of all the words used in the dataset is built. The dictionary includes all words variants like verb conjugations. Punctuation marks are also considered as words as I want the algorithm to learn the sentiments behind an entire sentence. Among the top 25 most words used, we have: ',', de, et, le, la, un, à, film, les, est, qui,. en, que, une, des, pas, du, ce, dans, !, pour, mais, a, on. Those are mostly French "stopwords" that are present in almost every French text with comparable frequencies. These words do not contain much information. Nonetheless, as I want the algorithm to be language generic I am not removing these words from the dictionary as it's generally done because identifying stopwords in a foreign language might be challenging. On the other hands, the less used words are often typos, names or very rare words that will add very little to the text analysis. I, therefore, keep only the 10.000 most frequent words in the dataset dictionary and ignore all the other ones. Considering that an average native English speaker knows about 30.000 words and a second-language English speaker knows about 10.000 words, the model is expected to be somehow limited, but not totally ridiculous.
- At this point, the review texts are turned to mathematical vectors. Words of the text are replaced by their index in the dictionary. Words that aren't present in the dictionary are simply skipped. In order to ease the processing, I fix the size of the vectors to 500 words. Text with more words are trimmed to the first 500 words and text with fewer words are padded with 0. After this, every single review text is represented by a 500 integer vector with components between 0 and 10.000 (the size of the dictionary). This is the input data for the deep neural network that we are going to use.
In a first simple model, I used the five following layers for the neural network architecture:
- An embedding layer which encodes the word integer (comprise between 0 and 10.000) as a float vector of 64 components. I could have used specific embedding algorithm like word2Vec or glove to perform this task, but I prefer to let the network figure out what is the best embedding for this particular dictionary, problem, and objective function. This layer takes as input a 500-vector of integer and returns a 500 x 64 float matrix.
- The following layer is a 1D-convolution layer made of 32 filters each with a length of 3 items. The goal of this layer is to learn the meaning of consecutive word patterns that may have a particular sense. Thinking about sentences like: "I did NOT like this movie". I expect this layer to catch that "NOT" preceding a verb actually negates the sense of the verb. As I use filters with lengths of maximum 3 words we should be able to catch that type of features at least in English and French (Dutch might be a bit more tricky as the distance between verb and negation can actually be large). This layer takes as input a 500 x 64 matrix and returns a 500 x 32 filter matrix. A Rectified Linear (ReLU) activation is used for this layer.
- Convolution layers ar traditionally followed by pulling layers which allows keeping the number of parameters in the model under control. In this case, we simply reduce the matrix dimension by a factor of 2 by keeping the strongest "word" in every two "words" window. Word is in a quote as it's not really a representation of the word anymore after it passed through the convolution layer. This layer, therefore, returns a matrix of dimension 250 x 32 which is twice smaller than it's input.
- It's time for the recurrent layer to come in. Here I used an LSTM layer, but I could also have used a GRU layer. I used 256 memory units for this layer in order to catch a maximum number of features within the entire text. A much lower number of smart neurons would certainly have worked as well since the length of the text is at most 500 words. The output of the layer is, therefore, a vector of 256 components.
- Finally, I used a dense layer which would reconnect all the features together and predict a single value between 0 and 1 corresponding to the text polarity. 0 would mean a rather negative text and 1 a rather positive text. I used a sigmoid activation for this layer as I want its output to be between 0 and 1.
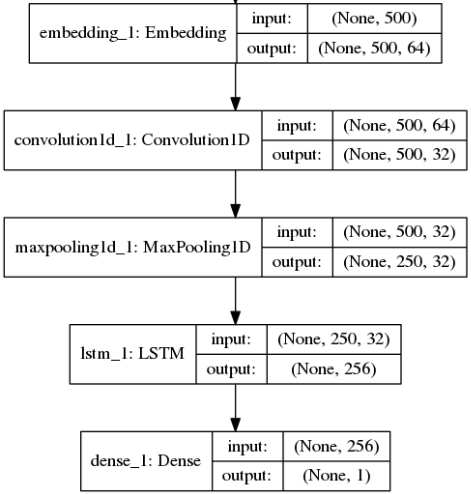
The table on the right summarizes the model architecture.
The model is trained on 80.000 reviews (20.000 are used for the model validation) using an ADAM optimizer and a binary cross-entropy objective function. Only reviews with a polarized score lower than 2/5 or higher than 4/5 are used for this training and they are marked as 0 or 1 polarity.
The total number of free parameters in the model is around 1000.000 and the training type is approximately 30 min per epoch on my Intel i5 laptop. After three epoch the accuracy is about 94% (tested on the validation sample).
Results examples on other movie reviews:
- "Magnifique . Drôle . Touchant . Cruel . Moderne . Humain. Beau . Inventif . Avec un superbe trio d'acteurs ." leads to a sentiment polarity of 0.999 (highly positive review).
- "Les personnages sont des paumés névrosés avec leur vision complètement négative de la vie. Ce film se veut original et provocateur à travers la vulgarité et la méchanceté gratuites. A part les premières scènes acceptables, on ne regarde malheureusement la suite qu'en apnée. Déplorable !" leads to a sentiment polarity of 0.048 (highly negative review).
Results examples on other sentences:
- "Je n'ai vraiment pas aimé ce film. Les acteurs sont mauvais et l'histoire est particulièrement nulle." 0.005 (negative sentiment).
- "J'ai vraiment aimé ce film. Les acteurs sont excellents et l'histoire est originale." 0.998 (positive sentiment)
- "Excellent" 0.942 (positive sentiment)
- "Ca ne s'annonce pas bon" 0.461 (average sentiment)
- "Vraiment étonnant" 0.854029 (rather positive sentiment)
- "Un peu de gaieté et de plaisirs pour ce soir 😀" 0.445237 (rather negative sentiment).
We see that although it's not always perfect, the algorithm catches most of the time the sentiment behind a sentence/text. Moreover, when it fails the text polarity is close to 0.5 which indicates some confusion regarding the sentiment. But for such scores, it is not possible to know if the algorithm is confused or if the text is neutral.
We can actually improve a bit the model using multiple outputs and a softmax in the last layer. In other words, we can train a model that would give us the probability that a text is negative (category 1), neutral (category 2) or positive (category 3). With this type of output, we can also measure the confidence of the algorithm regarding its prediction.
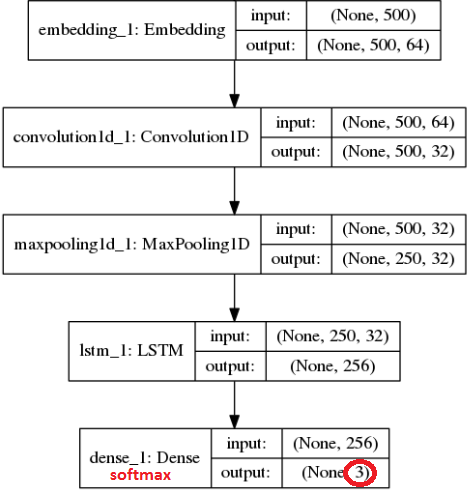
This more advanced modelis completely identical to the previous model (see figure) with the exception of the last layer which outputs a 3-float vector and uses a softmax activation (instead of a sigmoid) in order to guarantee a probability of being in one of the three categories. The objective function used for the training is this time a categorical cross-entropy.
Of course, this time we also included neutral reviews in the training phase which we write as a (0,1,0) score vector. (1,0,0) and (0,0,1) being used as score vector for the negative and neutral reviews, respectively. All the rest remains unchanged. The number of free parameters in the model is almost unchanged (still around 1.000.000) as the last layer only accounts for a tiny fraction of the model parameters. The training time is slightly larger than for the first model: ~40 min per epoch. But it is still quite reasonable. The model accuracy evaluated on the validation dataset is about 96%. The results for the same sentences as in the previous case are:
Results examples of other sentences:
- "Je n'ai vraiment pas aimé ce film. Les acteurs sont mauvais et l'histoire est particulièrement nulle." [ 0.97207683 0.02485518 0.00306799](negative sentiment with 97% probability).
- "J'ai vraiment aimé ce film. Les acteurs sont excellents et l'histoire est originale." [ 0.00260297 0.06905617 0.92834091] (positive sentiment with 93% probability)
- "Excellent" [ 0.03898903 0.09006314 0.87094784] (positive sentiment with 87% probability)
- "Ca ne s'annonce pas bon" [ 0.76711851 0.15689771 0.07598375] (negative sentiment with 76% probability)
- "Vraiment étonnant" [0.05729499 0.11347752 0.82922751] (positive sentiment with 83% probability)
- "Un peu de gaieté et de plaisirs pour ce soir 😀" [ 0.40064782 0.21832566 0.38102651] (mitigated sentiment).
We can see that the last sentence is clearly confusing the algorithm which isn't capable of identifying a clear sentiment behind this sentence. But this time, we can spot that all the algorithm predictions are under a 50% probability which is therefore rather weak.
The model can, of course, be further customized and improved, but I am stopping here for this tutorial. For the most curious one, here is the code I used to define and train the advanced model. As you can see, there is nothing really striking there.
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers.convolutional import Convolution1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
...
# create the model
embedding_vecor_length = 64
model = Sequential()
model.add(Embedding(top_words, embedding_vecor_length, input_length=max_review_length))
model.add(Convolution1D(nb_filter=32, filter_length=3, border_mode='same', activation='relu'))
model.add(MaxPooling1D(pool_length=2))
model.add(LSTM(256, dropout_W=0.2, dropout_U=0.2))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
model.fit(Sequences[:split], Labels[:split], nb_epoch=3, batch_size=64)
# Final evaluation of the model
scores = model.evaluate(Sequences[split:], Labels[split:], verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
Have you already faced similar type of issues ?
Feel free to contact us, we'd love talking to you…Don't forget to like and share if you found this helpful!